You finish a user interview, open your AI tool, paste in the transcript, and hit generate. The summary comes back clean. Confident. Completely hollow.
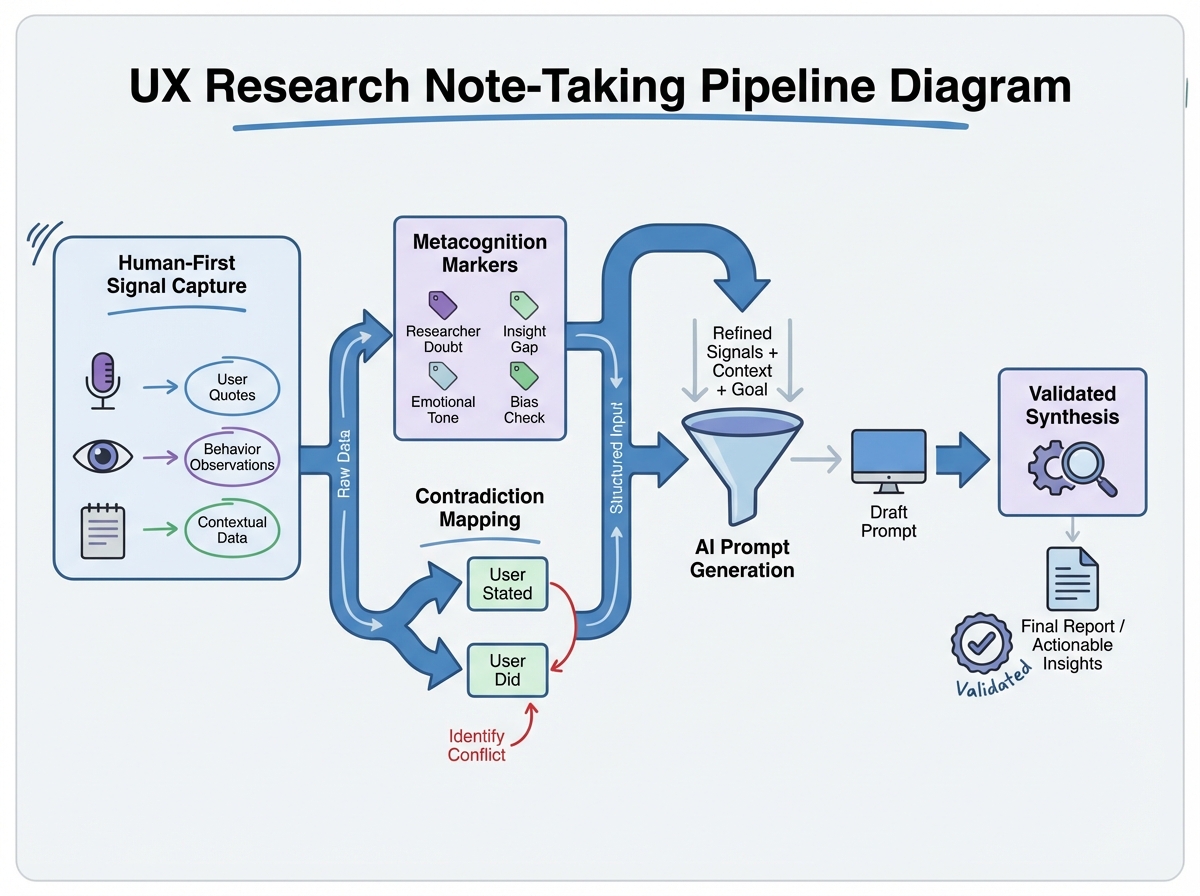
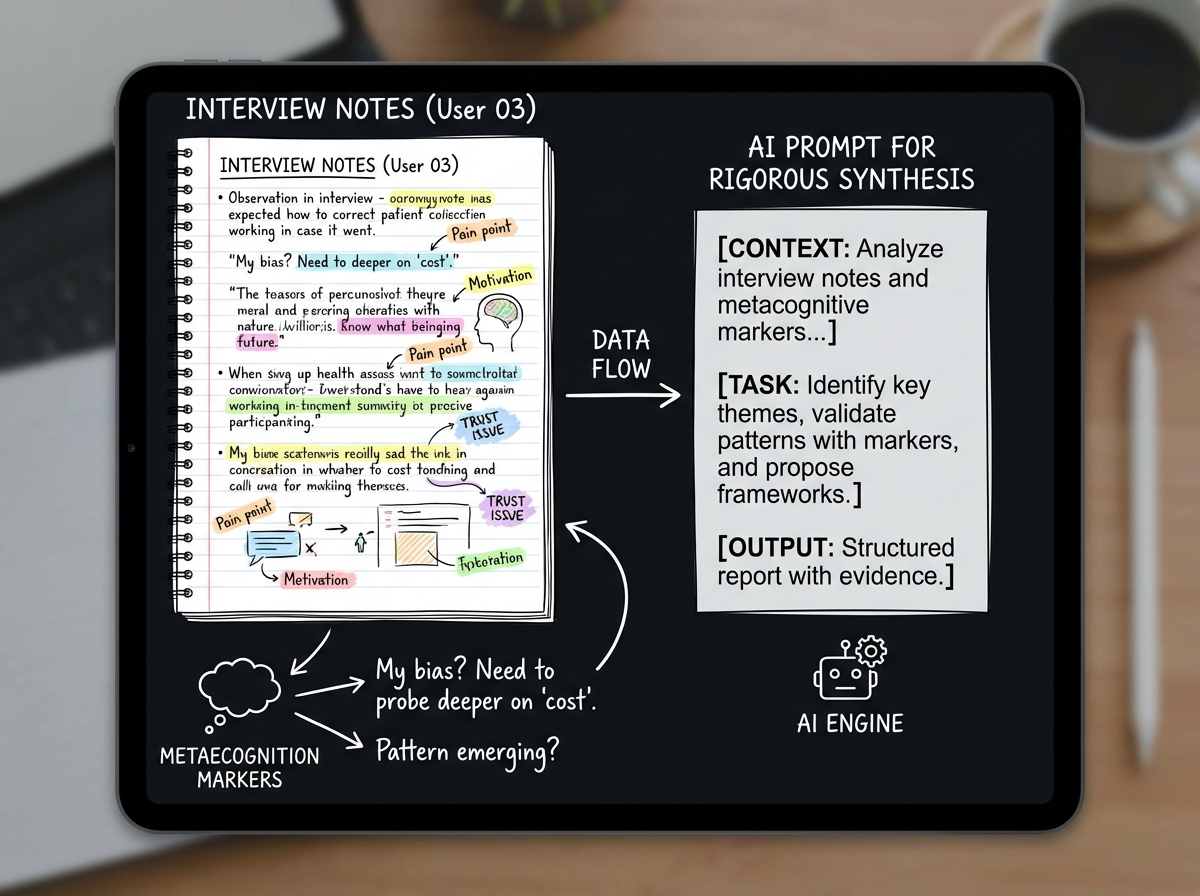
If you’re looking to learn UX research note-taking that actually holds up under synthesis, the answer isn’t a better transcript tool — it’s rebuilding what you capture before you ever touch AI. Strategic note-taking for UX research means recording not just what participants say, but what you notice, doubt, feel surprised by, and sense is contradicted by their behavior. That layer of human signal is what makes AI output something you can stand behind instead of something you have to second-guess.
- You don’t have a transcription problem — you have a perception problem, and AI makes it worse if your notes are thin
- The researchers who get the most out of AI are the ones who go into sessions with a notation system, not just a recording app
- Your intuition during an interview is data — but only if you capture it in a form AI can work with
What “Strategic Note-Taking” Actually Means in UX Research
Most people treat note-taking as a backup for the recording. Strategic note-taking for UX research is something different: it’s the practice of capturing your inner responses alongside observable behavior — surprise, confusion, the moment a participant said one thing and did another. These aren’t soft observations. They’re the signals that distinguish a rigorous researcher from someone who operates outputs.
The core distinction worth understanding:
| Type | What It Captures | AI Can Replace It? |
|---|---|---|
| Transcript note | Verbatim or paraphrased speech | Yes |
| Observation note | Visible behavior, hesitation, tone | Partially |
| Interpretation note | What you think it means | No — must be flagged separately |
| Metacognition marker | Your gut signal in the moment | No — must be written by you |
| Contradiction flag | Gap between words and actions | No — requires present awareness |

The target reader here is a UX designer or researcher who already runs interviews but has started leaning on AI summaries — and has a nagging feeling the output isn’t quite earning the trust they’re giving it.
Three things that are true and most people don’t say out loud:
- Emotional arc data disappears completely in transcripts — AI has no idea a participant’s tone shifted halfway through
- The observation/interpretation split is the most violated rule in qualitative research, and almost no one flags it in real time
- AI doesn’t hallucinate randomly — it hallucinates confidently in the direction of your weakest notes
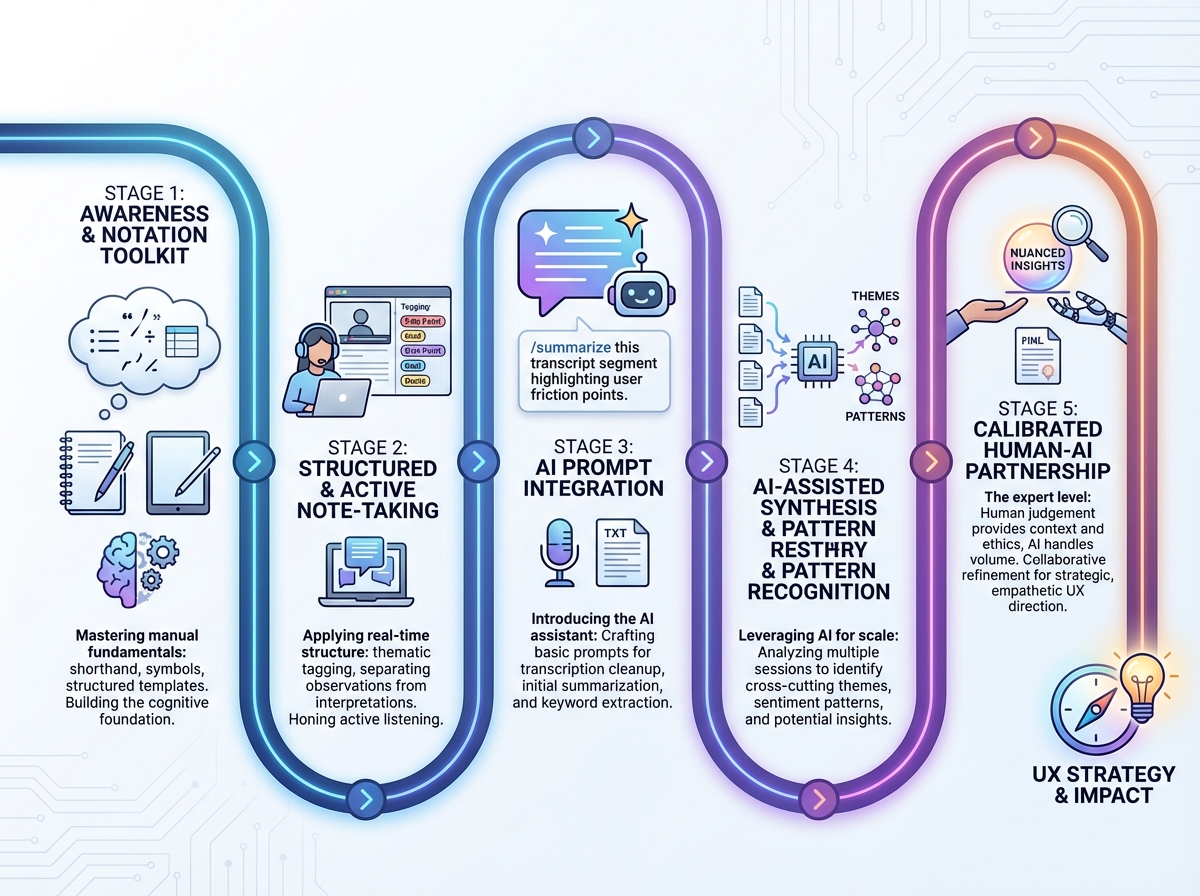
How Long This Actually Takes to Build Into Your Practice
| Stage | What You’re Working On | Time |
|---|---|---|
| Orientation | Understanding human-first → machine-second logic | 1–2 hours |
| Toolkit acquisition | Learning notation types: markers, arcs, anchors | 2–3 hours |
| Drill practice | Role plays, contradiction mapping, obs vs. interp | 2–4 hours |
| AI integration | Prompt patterns, validation loop, evidence trail | 2–3 hours |
| Ethics and calibration | Bias awareness, AI partnership calibration | 1 hour |
| Total | From concept to embedded practice | 8–13 hours |
Order matters more than speed here — skipping straight to AI prompts without the notation foundation is exactly how you end up with synthesis that sounds right but can’t be defended. And if it takes you longer than two weeks to feel fluent with the markers, that’s completely normal — the friction usually comes from unlearning the habit of mixing observations and interpretations, not from the technique itself.
Why Your Awareness Is a Research Instrument, Not a Bonus
The hardest shift is accepting that what you notice during an interview isn’t contaminating the data — it’s part of the data. When you feel a flicker of confusion because a participant described loving a feature they never actually used, that confusion is a signal. If you don’t write it down with a notation that marks it as an inner signal rather than an observation, it evaporates. The transcript won’t carry it. The recording won’t surface it. AI definitely won’t invent it.
This is where most researchers lose rigor without realizing it. They’re meticulous about capturing what participants say, somewhat good at capturing what participants do, and almost entirely silent about what they notice. That third layer — metacognitive awareness as a research instrument — is what makes human-first note-taking categorically different from just having clean notes.
The practical move is deceptively simple: develop a marker system that lets you flag inner signals in real time without breaking your listening flow. Something as minimal as a bracketed “!” for surprise, “?” for confusion, or “~” for something that felt off. These become the anchors for your AI prompts later — instead of asking AI to summarize, you’re asking it to interrogate a specific signal you already named.

The Notation Toolkit That Changes How Sessions Feel
There’s a moment in most interviews where something contradicts something else. A participant says the onboarding was easy, then spends four minutes getting lost in it. If you’re only transcribing, that contradiction lives in two separate parts of the document and AI will average them into a neutral statement about moderate ease. Contradiction mapping means flagging both signals at the moment of capture and linking them explicitly — so the tension stays alive in your notes rather than being smoothed out in synthesis.
Emotional arc tracking works differently. You’re not rating sentiment — you’re drawing a line. You’re noting when the energy in the room shifted, when a participant leaned in versus pulled back, when their pace changed. That arc is invisible to transcripts and completely absent from AI summaries, but it often carries the most diagnostic signal in an entire session. The participant who was engaged for the first twenty minutes and disengaged exactly when you showed the new feature — that timing is data.
Context anchors are the easiest to under-use. These are notations that capture why something happened, not just that it happened. A participant struggling with a filter isn’t just struggling with a filter — they came in from mobile, they’re used to a different product pattern, they mentioned offhandedly that they’ve never used a sort function. Context anchors tie behavioral observations to situational causes, which is what makes them useful in synthesis instead of just interesting in isolation.
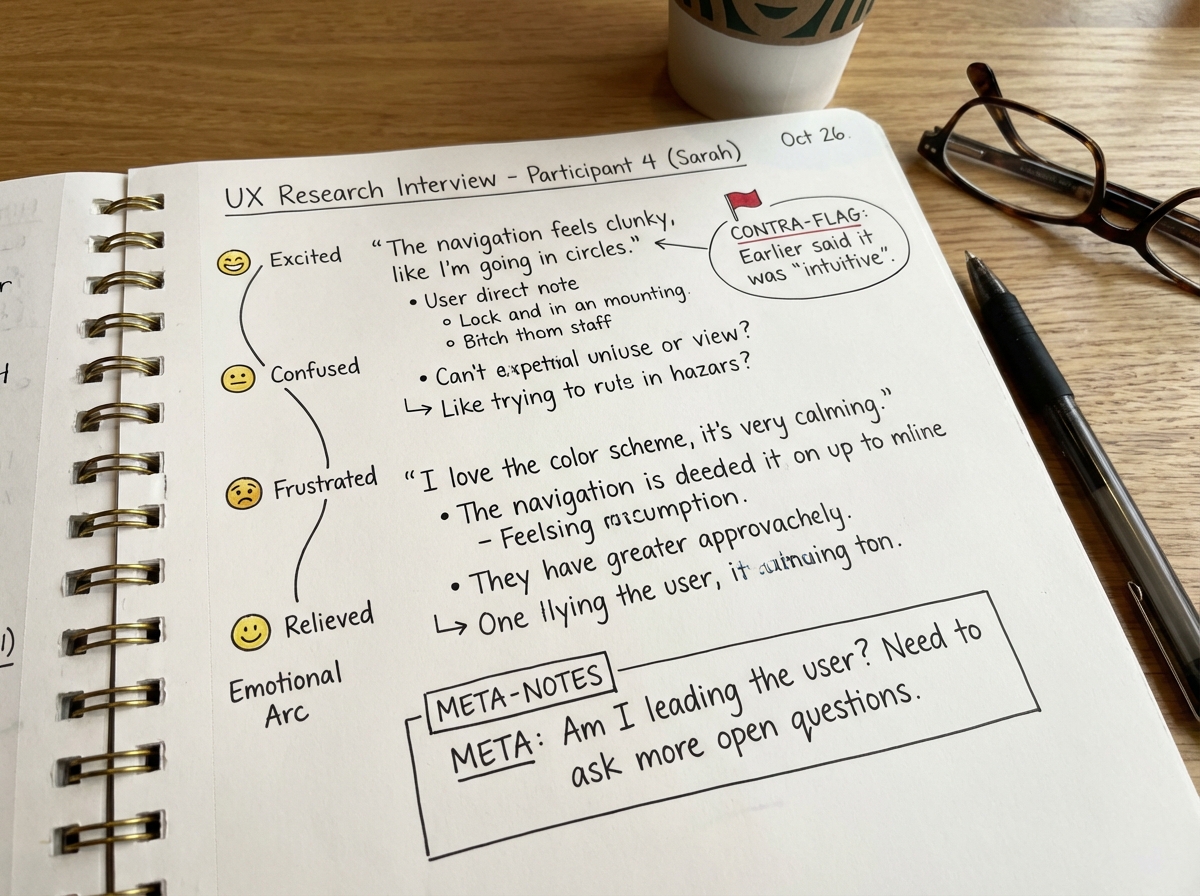
The Observations vs. Interpretations Split That Most People Skip
The single biggest mistake people make when learning UX research note-taking is writing interpretations in their observation column and not realizing they’ve done it. “She found it confusing” is an interpretation. “She paused for six seconds, clicked back, and said ‘wait, where did that go'” is an observation. The difference seems pedantic until you’re in synthesis and you realize you’ve built a theme on a layer of inference with no behavioral evidence underneath it.
Keeping these explicitly separate isn’t just a hygiene rule — it’s what makes your AI prompts defensible. When you prompt AI with a clearly labeled observation, you can ask it to generate interpretations and then critique them. When your notes are already fused — observation plus interpretation in one sentence — you’ve handed AI a conclusion disguised as evidence, and it will treat it as evidence.
The post-session habit that locks this in is a five-minute workflow: immediately after the interview ends, before you open anything else, go through your notes and do one pass where you flag anything that slipped into interpretation without a paired observation. Move those to a separate “hypotheses” section. Now you have two clean layers — what you saw, and what you think it means — and AI can be instructed to work with both separately.

Writing AI Prompts With Research Rigour
Most AI prompts for UX research look like this: “Summarize the key themes from this interview.” That’s not a prompt — it’s an abdication. You’re handing AI a transcript and asking it to decide what matters. The frame it chooses will be driven by frequency and surface language, not by the tensions, surprises, and contradictions that your human perception flagged.
Prompts grounded in research rigour look different. They reference specific signals: “I noticed a contradiction between what this participant said about ease of use and the behavior I flagged in minute fourteen — generate three possible interpretations of that gap.” Or: “Here are my metacognition markers from this session. For each one, identify whether there’s supporting or contradicting evidence in the transcript.” You’re using AI to interrogate your signals, not to replace the act of having them.
The validation loop — draft, critique, verify, document — is what separates a trustworthy synthesis from a confident one. AI gives you a draft interpretation. You critique it against your raw observation notes. You verify it by checking whether there’s transcript evidence. You document the confidence level explicitly. That last step is the one almost everyone skips, and it’s the one that prevents fabricated synthesis from compounding across sessions.
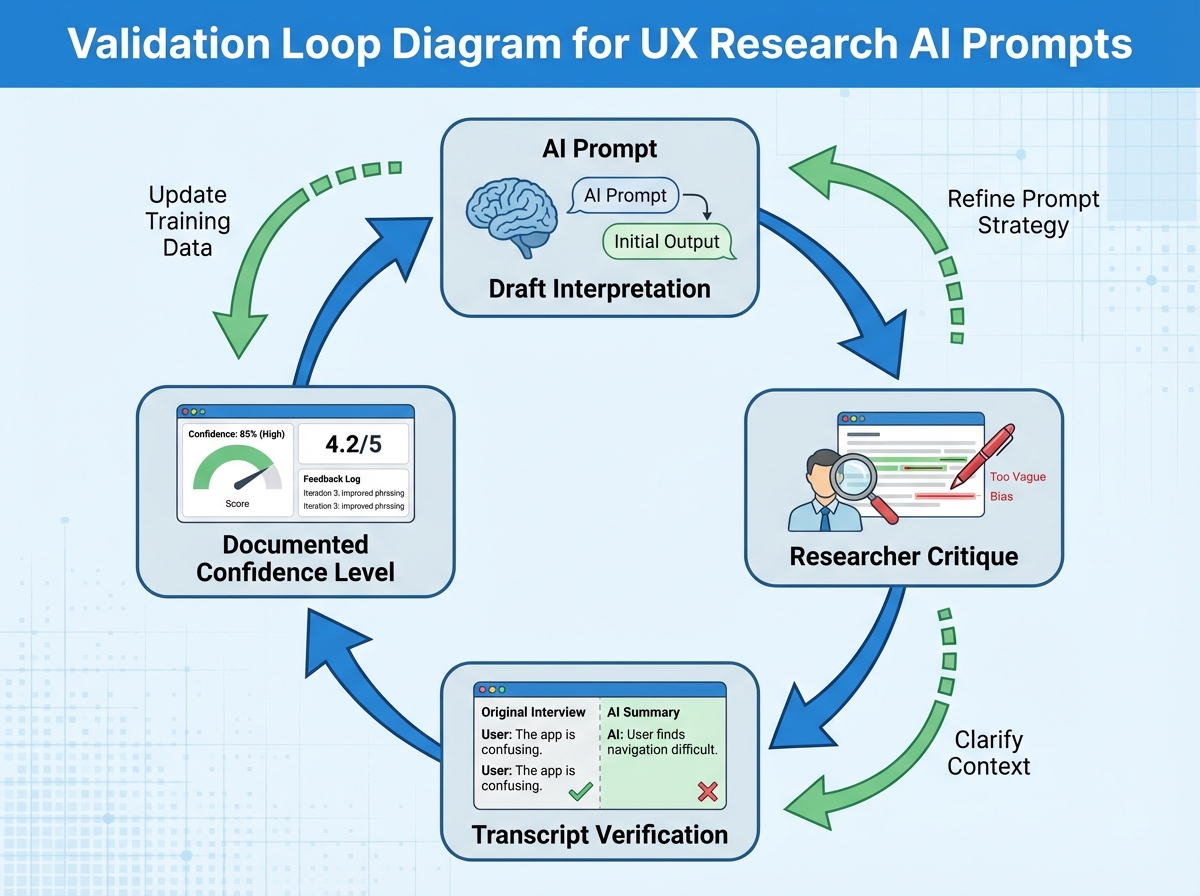
Calibrating the Human-AI Partnership Without Losing Either Side
There’s a version of AI-assisted UX research that looks rigorous but isn’t: the researcher uses a solid notation system, captures great signals, and then hands everything to AI and accepts the synthesis because the input was strong. Input quality doesn’t guarantee output quality. AI can still flatten emotional arcs, smooth over contradictions, and generate confident-sounding themes from thin evidence — it just does it with your notation as a veneer.
Calibration means actively testing whether AI is adding or subtracting from your understanding. One concrete practice: after getting an AI synthesis, read it against your raw notes and ask how many of your metacognition markers actually made it into the output. If AI identified four themes and you flagged six distinct surprise moments that don’t map to any of them, you have a calibration gap — and the synthesis isn’t done yet.
The ethical dimension of this is real and underappreciated. When you present AI-generated insights to a product team, the team is implicitly trusting your perception, not the AI’s pattern-matching. If your workflow allows AI to choose the frame without challenge, you’re presenting machine confidence as human judgment. The evidence trail — documenting which signals led to which hypotheses, at what confidence level — is what lets you stand behind your work in that room.
Immediately actionable moves for your next research session:
- Build a three-symbol metacognition system before your next interview — pick one symbol for surprise, one for confusion, one for “something’s off,” and use only those three until they’re automatic
- Write your first post-session hypothesis within five minutes of the interview ending — before reviewing notes, write one sentence about what you think you noticed, then go check whether your observation notes support it
- Create a dedicated “contradictions” section in your note template — every time a participant’s words and behavior don’t match, it goes there with a timestamp, not buried in the main flow
- Never paste a raw transcript into AI without a accompanying prompt that references at least one specific signal you flagged — this forces you to engage with your own notes before offloading to synthesis
- Rate every AI-generated theme with a confidence level before you use it — high, medium, or low, based on how many distinct observation notes support it, not how plausible it sounds
- Do one calibration check per session — count your metacognition markers, then count how many of them appear in the AI synthesis; if fewer than half made it, push back on the output
- Separate your observations document from your interpretations document — even if it’s just two columns in the same file, the physical separation changes how you write in real time
- Before any synthesis presentation, trace one key insight back to a raw observation note — if you can’t do it in thirty seconds, the insight isn’t ready to present
Leave a Reply